I want a guest network to mess around with, I mean what are guests for after all?
What other reasons are there for having a guest network?
Well, say you don’t want to give out the password to your actual home network. You may want to limit activity of guests. You do not want guests to be able to communicate with personal devices on your network. You might have some malicious/untrustworthy friends and you want to keep yourself safe. So many reasons.
Worry not peoples, there is an easy way to set this up on Tomato Shibby and most other new router firmwares! The following steps use the tomato firmware web UI. By default, the UI can be accessed on 192.168.1.1 by a computer connected wirelessly to the router.
First thing is first, a new bridge has to be greater for this guest network. This bridge can be created in the Basic -> Network section under LAN. Simple click ‘Add’ and enter in your desired settings.
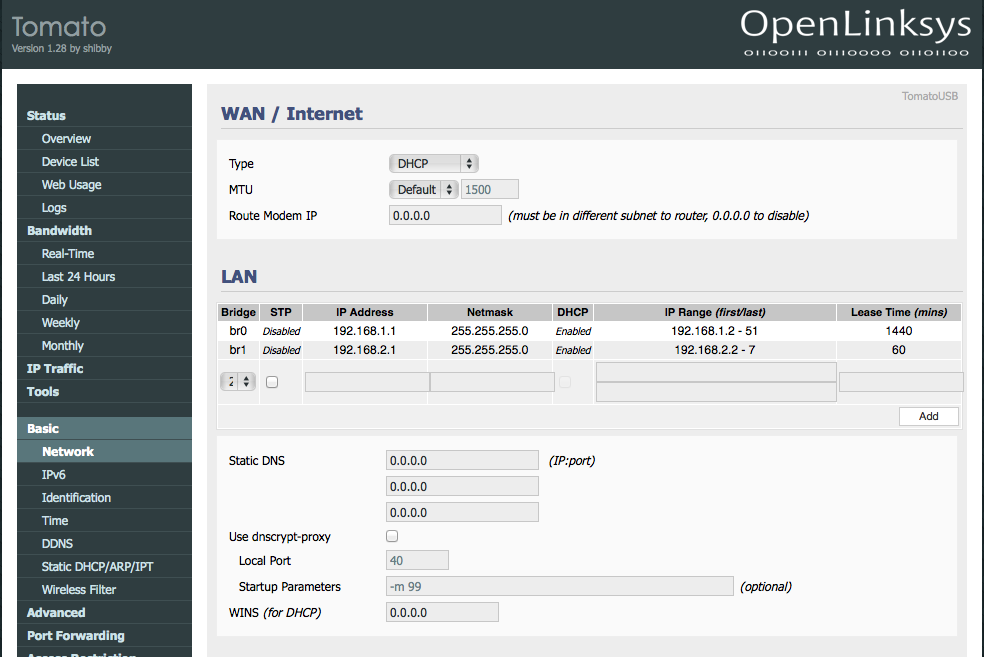
The bridge I created (br1), is pictured above. It is set to use IP addresses 192.168.2.2-192.168.2.7 with the router hosting on 192.168.2.1. I’m only allowing up to 6 guests. I don’t want my experience to get bogged down by guests so I limit the amount of addresses available to them hence limiting the number of guests able to connect. Also, I set the lease time for guests to 60 minutes, they don’t need a long lease time. Save your progress.
Sweet, so I now have this bridge. Now I must assign it to a VLAN.
“In computer networking, a single layer-2 network may be partitioned to create multiple distinct broadcast domains, which are mutually isolated so that packets can only pass between them via one or more routers; such a domain is referred to as a virtual local area network, virtual LAN or VLAN” (Wikipedia).
I don’t want guests accessing my stuff, so I will put them on a separate VLAN. Create a VLAN (for me it was 3) and assign the new bridge (br1) to it in Advanced -> VLAN under VLAN.

In my setup above, I’m not expecting guests to connect directly to a port on the router so I did not configure any of them. I expect guests to just connect wirelessly. Save your progress after setting this up.
Now time to set up the wireless SSID for the guests. Go to Advanced -> Virtual Wireless. Add the wl0.1 interface (or whatever one you want to use) and set it to use the new bridge (br1). Give it any SSID you want, I chose to call mine Guest, as seen below. Save it.
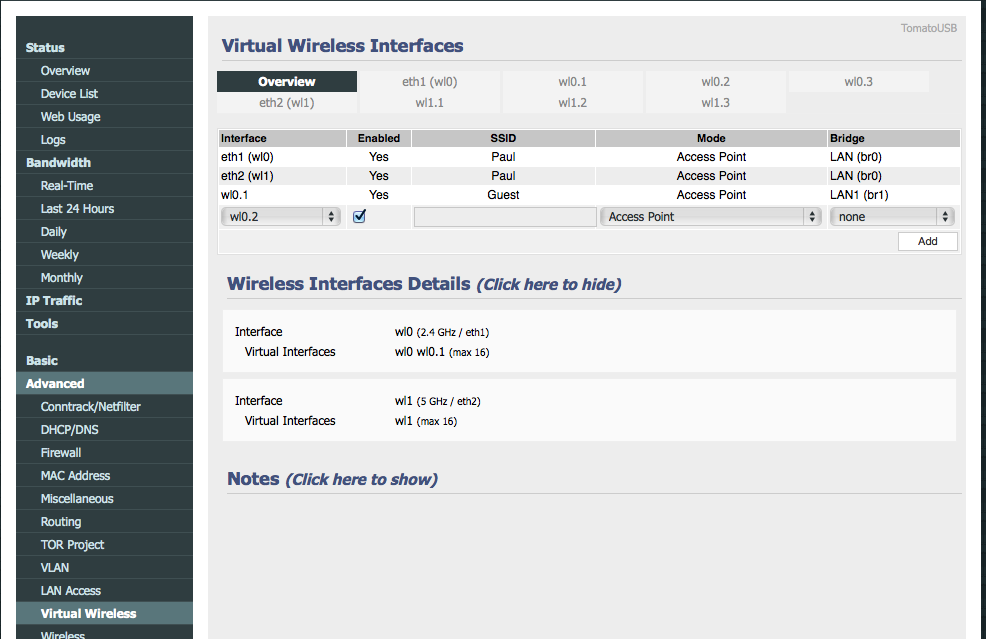
You can configure settings for the wireless interface by selecting the coordinating tab (wl0.1) from the top of the page. For instance, you might want to give it security. For now, I gave mine security but I don’t think I’ll keep it. Save it.
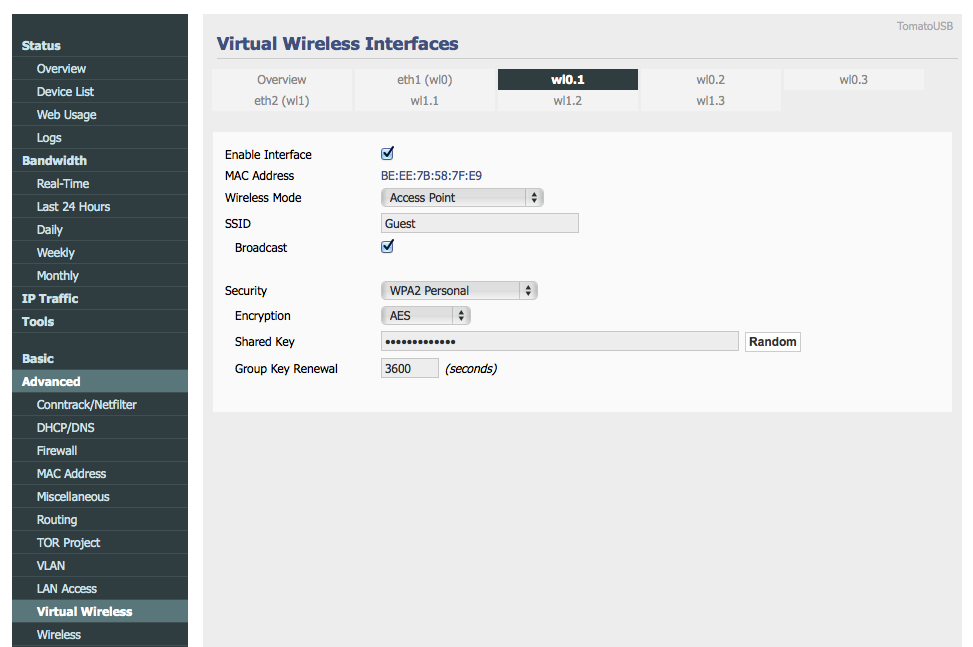
Finally, double check all is set correctly in Advanced -> VLAN.
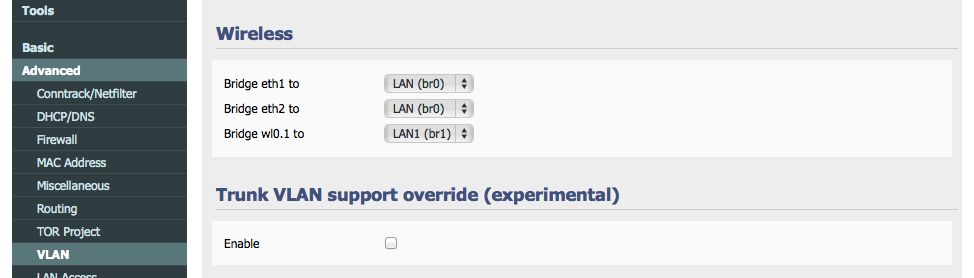
Basically, look to make sure the right bridge is setup to the right wireless interface. Save it.
Next to make sure my guest VLAN users cannot access my private network devices I added a few block forwarding IP table rules. To do this, add the following commands in Administration->Scripts under Firewall:
iptables -P FORWARD DROP iptables -A FORWARD -i eth0 -o br0 -j ACCEPT iptables -A FORWARD -i br0 -o eth0 -j ACCEPT iptables -A FORWARD -i eth0 -o br1 -j ACCEPT iptables -A FORWARD -i br1 -o eth0 -j ACCEPT
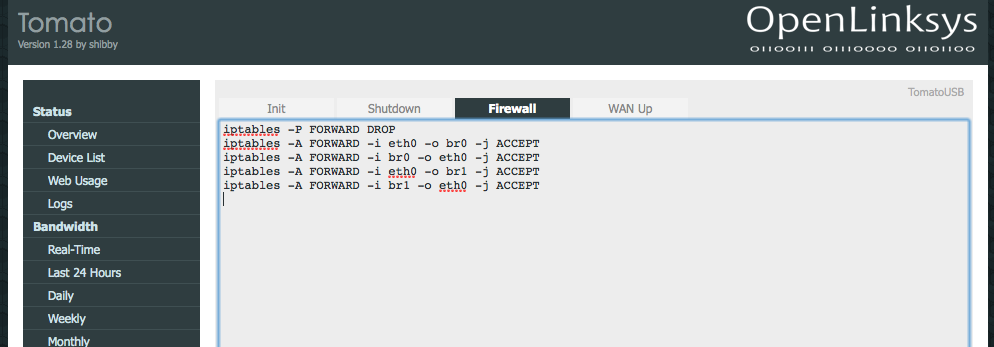
These rules first drop all forwarding communications. Following, the next rules set the firewall to allow communications between both bridges and the external world (eth0) only. This way the networks cannot talk to each other but still have internet connectivity. Save and you’re done with the basics!
I went ahead and added a few extra things like a splash page for guests and I also limited their bandwidth activity. I’ll explain how to do this in a later post, this one is too long.
What about a post on how to toggle just the virtual wireless (e.g. to assign it to the router’s button). I’d find this very useful!
Sorry for hijacking your post but I worked out a solution that works for me. Just in case someone else is looking for this:
if [ “`nvram get wl0.1_radio`” = “0” ]; then
/bin/nvram set wl0.1_bss_enabled=1
/bin/nvram set wl0.1_radio=1
/bin/nvram commit
service wireless restart
echo “Switching on virtual wireless”
else
/bin/nvram set wl0.1_bss_enabled=0
/bin/nvram set wl0.1_radio=0
/bin/nvram commit
service wireless restart
echo “Switching off virtual wireless”
fi
Thanks for the comments! That’s something I’ll try out.
Thanks for this post, very helpful. One issue though – the firewall rules are inconsistent with the numbering of your VLANs. In the setup as described and pictured you should be allowing access to/from vlan2, not 1.
Thanks for the catch, I’ve updated the post. I ended up changing the rules entirely. Instead of controlling on the vlan level I set controls on the bridge access forwarding.
“Finally, double check all is set correctly in Administration -> VLAN.” should be …Advanced -> VLAN.
Thanks for the useful write-up.
I use “Basic – Wireless Filter – Permit only the following clients” to limit access to my home network. Will these limits (restrictions) also be applied to the Guest Wireless Access (wl0.1) you setup above?
Great post! Thank you so much for this!
Great post. Thank you very much for putting it together. How can I test to make sure that the guest network can’t access my main home network?
I had a shared network drive located on home network. To test that my guests couldn’t access it, I connected to the Guest network and tried to access the drive. You could also try pinging machines on the home network from the guest and if the packets get dropped, you’re good. However, Windows by default now (I believe since Windows 7) blocks pings. Either unblock pings or use another device with a different OS on your home network.
Let me know if this works for you!
You may want to include something in the firewall rules to prevent guest users from accessing the router configuration.
Yes, would be nice. For now…just a strong password!
re: prevent guest users from accessing the router configuration …. I tryied to set up a rule in “Access restriction” menu …. forbidding to visit 192.168.1.1 for IPs of my guest network (in my case 192.168.2.1 – 192.168.2.50) but it did not work…. anybdy knows why? any other idea?
you need to add this to the firewall…
iptables -I INPUT -i br1 -m state –state NEW -j DROP
iptables -I INPUT -i br1 -p udp -m multiport –dports 53,67 -j ACCEPT
Just to be sure, It is right to use eth0 in the iptable rules even if there is no mention of eth0 inthe interface of Tomato by Shibby? I do have, just like you, eth1 and eth2 mentionned in the interface but no eth0.
Just figured by myself 1 minute after posting the question … eth0 being the WAN, I do understand now.
I am using an Airport Express to stream my music to my sound system. The AE connects wirelessly to my router. After setting the guest account, my Airport won’t connect anymore. I guess it has to do with the firewall setting.
Can anyone give me a clue on how to fix this?
Thanks for the few tutorials on Tomato firmware. It is great and helps a lot in getting stuffs working.
However, I have one question about the firewall rules. Is there really a reason for them? Cause with the both the networks in separate VLAN and subnet, it is already good enough to have them separated. I tried ping each other and sure enough they are not able to ping.
No problem! When I was setting this up, I had an issue with devices being able to ping across VLANs. I believe this was due to another issue but I had setup the firewall rules to resolve it. I didn’t retest without firewall rules. If you were pinging other Windows machine on the network, ping by default is turned off.
theoretically they should not be able to ping each other unless you create a bridge between them. I tried the ping on linux and windows machine. And it does not ping. My windows I have ping allowed in firewall as I use this a lot.
I just tried this again and sure enough
Thank you for this tutorial.
I have a question. If I setup router to work as AP, I should be able to create guest network?
THanks
Awesome! Thank you!
Hi..
Great post.. how come you have eth1 & eth2?
I only get the option for eth1
—
so, under Virtual Wireless Interfaces I have
eth1(wl0)
wl0.1
the only other options are wl0.2 & wl0.3
What am I missing?
Can a 5ghz guest account be added?
Hi
Followed the tutorial and all seemed to go well – wireless VLAN setup, can see the new SSID and
can connect to it and it’s giving me the correct IP, the one setup for the VLAN.
However, I cannot get to the internet.
Any help would be great.
Thanx,
Darren.
/////////////////////////////////
Win 7 Ultimate
Cisco Linksys E2000
Tomato Firmware v1.28.7500 MIPSR2Toastman-RT K26 VLAN-Std
Chipset Broadcom BCM4716 chip rev 1 pkg 9
CPU Freq 354 MHz
Flash RAM Size 8 MB
It might be that you need to clear your network settings for your windows computer and reconnect. It might be seeing the old configuration as the new.
@K4Paul
Hi..
I have limited the bandwidth on the guest account (br1) and it works if I connect to it wirelessly, but not if I connect directly using port 4 after assigning it to br1. – can you please advise what would assigning port 4 to br1 does?
Hi Darren,
Does it work? I’ve got the same problem.
I’ll can connect to the guest wifi and get ip address, but no internet.
thanks
Hi! I have a WRT54GL and I wanted to setup this, but I got error message only: “warning: WL driver reports BSSID 00:00:00:00:00:00”. What can be the problem?
Most likely that router does not support VLAN’s at all. 🙁
Is it necessary to setup those iptable rules if you already placed the br1 into a vlan?
Since they would not be able to access devices on the private network unless you added entries into “Advanced>LAN Access” to allow the inter-vlan communication.
Just wondering in case I missing something since I’m pretty new to tomato.
Hi, trying to follow your instructions, but don’t have the :Virtual Wireless” option under “advance” is there another path I can use?
i want to make my guest network to access to internet only for specific time. like from 9pm to 12am. is it possible?
by turning down the br1 or by its ip range??
Thanks in Advance.
Thank you for this tutorial!
I got it working perfectly on my Asus N12. Unfortunately, it doesn’t seem to work in conjunction with OpenVPN on the router. When I have the OpenVPN client turned off, both regular and guest networks work normally. When I turn the OpenVPN client on, the regular network works through the VPN, but the guest network won’t connect to the internet at all.
Any ideas on how to change this? I was hoping I could have one network go through the VPN and one network bypass it, so just by switching networks my devices could geolocate in different parts of the world.
Hi..
The guest account breaks Dns… I use OpenDNS as my dns server and it stops working every time I add a guest account.. once I disable it, the OpenDNS filtering starts working again.
Thanks for the tutorial. Any advice for setting this up to work in multiple routers that are on two opposite ends of the house? They are hard wired between each other.
Hi, thanks for the nice tutorial for Guest WiFi.
As described in the tutorial i added also the Firewall rules by iptables. I paste these after the one i had already in the Firewall tab.:
iptables -I FORWARD -i br0 -o tun11 -j ACCEPT
iptables -I FORWARD -i tun11 -o br0 -j ACCEPT
iptables -I INPUT -i tun11 -j REJECT
iptables -t nat -A POSTROUTING -o tun11 -j MASQUERADE
source: https://support.hidemyass.com/hc/en-us/articles/202798226-Selective-routing-for-Tomato-firmware-Per-source-IP-address
Now i discover in the WAN up tab that these rules work no longer:
sleep 60
ip route flush table 200
ip route flush cache
ip rule add from 192.168.1.150 lookup 200
VPN_GW=`ifconfig tun11 | awk ‘/inet addr/ {split ($2,A,”:”); print A[2]}’`
ip route add table 200 default via $VPN_GW dev tun11
IP 192.168.1.150 is now no longer behind VPN.
Can you provide a solution which doesn’t “conflict” Guest WiFi and VPN settings ?
Thanks in advance
Hi, thanks for the great instructions on wireless guest account. I also have th guest account working, but still no access to the internet. Other site appear to indicate that the script is missing a line in the firefall script (script line by eibgrad):
iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -j MASQUERADE
Do you agree? if yes: just add underneath your 5 lines of script to make it work?
Thanks.
Trigonos
I’ll try it out.
Worked perfectly, and just what I was looking for, as my geek daughter is planning on throwing a party in a few weeks. All I could envision is a house full of Peabody’s being nosy on my LAN!
I won’t be home, so QOS/bandwith issues are theirs alone, but I’ll be looking into that in the future. Keep up the good work, and Thank You!
=======================
WRT54GLv1 running
Tomato 1.28.7633.3-Toastman-VLAN-IPT-ND ND VPN
Hello @K4Paul,
I appreciate your sharing your knowledge in this area. It’s difficult to find valuable information like this online (and that praise is coming from a pretty creative scourer, if I do say so myself). Thanks again for contributing to the community of knowledge.
Thank you
Hi, I would like to have my main LAN and wifi network using eth0 to access the internet and guest network using my openvpn client connection. Can I follow you tutorial but change the firewall script to:-
iptables -P FORWARD DROP
iptables -A FORWARD -i eth0 -o br0 -j ACCEPT
iptables -A FORWARD -i br0 -o eth0 -j ACCEPT
iptables -A FORWARD -i tun11 -o br1 -j ACCEPT
iptables -A FORWARD -i br1 -o tun11 -j ACCEPT
will this work?
Let me know, I don’t see why not. I know that the setup is fragile. Things like a splash page can get in the way of executing iptable rules.
Thanks, it work on Tomato Firmware 1.28.0000 -130 K26ARM USB AIO-64K. I followed your tutorial and skip the firewall script. Three things I did to VPN setting. 1.Basic->Static DNS 8.8.8.8 and 8.8.4.4 2.VPN Tunneling-> OpenVPN Client-> Advance-> Select Ignore Redirect Gateway 3.VPN Tunneling-> OpenVPN Client-> Rounting Policy-> Select Redirect throught VPN, enable, from source IP and key in the IP address of BR1. Cheers!
Hi,
Is is possible to share port 4 on for guest network also ? (in case I want to make a long cable and place a AP point for guest access)
Hi, I followed the tutorial and it works except the firewall rules. Guests can still access main network (LAN1/br1) even after reboot.
Hi, although I have added the iptables rules to the additional firewall scripts, I’m still able to access the main network (LAN/br0) even after reboot.
Does anybody know what’s wrong?
ASUS RT-AC68U with Tomato by Shibby v1.28-130.
I had the same issue when I was using a splash page. Once I removed it everything worked again.
I’m having issues with guest networking accessing the main network. I have no splash page yet either. I am using a R7000 router and rebooting has resolved it.
I also have had this issue with older Asus routers in the past. I can’t get the firewall settings to work.
This worked to block br1 for access to router gui and br0 clients.
iptables -I INPUT -i br1 -m state –state NEW -j DROP
iptables -I INPUT -i br1 -p udp -m multiport –dports 53,67 -j ACCEPT
Thank you for these script-lines, unfortunately the –state and –dport was changed to – (1 long minus), which led to the script not working properly.
Some research on iptables led me to change it to –.
Just to keep in mind, if you copy & paste these 2 lines.
Dear moderator,
In my post the double minus was also changed to 1 big minus while posting…so my post doesn’t make too much sense anymore.
May I ask you to change my post to this one, thanks in advance:
Thank you for these script-lines, unfortunately the –state (2 minus) and –dport (2 minus) was changed to –(1 long minus), which led to the script not working properly.
Some research on iptables led me to change it to — (2 minus).
Work like charm now! 🙂
Just to keep in mind, if you copy & paste these 2 lines.
Your instructions were very helpful, I have the Guest Wifi working great on Tomato 1.28 by Shibby FW. Is there any way to limit bandwidth for a particular device on guest wifi (br1). In the BW menu, we can select IP or MAC addresses to limit BW only for br0, but for the br1 section, there is no way to select a ip address. Can this be achieve in any way? thanks
Was able to get the guest network setup, but when surfing the web, I get prompted for a password for the other VLAN.
The DNS server is on my internal private lan and I would like guests also to use this DNS server I think I need some IP tables rule to give the guest network access to the private lans DNS server.
Can somebody help me?
Hi,
Thanks for the great article. I used this guide to setup a separate bridge and VLAN to control guest bandwidth on my network and it’s working great. However I still cannot ping devices from br0 to br1, and thus I cannot remotely go to my AP’s web GUIs. My setup can be seen here: http://superuser.com/questions/998068/how-to-access-an-ap-on-a-separate-vlan, and I’ve also added the iptable script modified to let br0 to connect to br1, and vice versa, but still no luck. If you don’t mind could you take a look and see what I did wrong please? Thank you
Thanks for the guide. I used it but changed the iptables rules. I wanted three things to happen
1. Private network cannot talk to guest clients
2. Guest network cannot talk to private clients
3. Guest network cannot access the router (www, https, ssh, telnet)
—-
iptables -I FORWARD -i br1 -o br0 -m state –state NEW -j DROP
iptables -I FORWARD -i br0 -o br1 -m state –state NEW -j DROP
iptables -I INPUT -i br1 -p tcp –dport telnet -j REJECT –reject-with tcp-reset
iptables -I INPUT -i br1 -p tcp –dport ssh -j REJECT –reject-with tcp-reset
iptables -I INPUT -i br1 -p tcp –dport www -j REJECT –reject-with tcp-reset
iptables -I INPUT -i br1 -p tcp –dport https -j REJECT –reject-with tcp-reset
With this instruction, I have get the guest wifi work at 2.4Ghz.
I want to secure my own 2.4GHz and 5Ghz wifi (192.168.1.*) with a MAC filter, instead of passwords for the best performance and a lower temperature of my router.
How can I leave the guest wifi (192.168.2.*) out of the mac filter?
I don’t think the guest wireless feature will work if you are using the router as a ‘wireless bridge’. Is that correct ? Thank you.
Hi,
Great post, thanks! How can it come, that I have not done the iptables part, but it still works as you described: both networks can reach the internet but they can’t see eachother.
I set up a VLAN as above (thanks for the clear write-up!), but want to block access as posted by ‘Frank’ – particularly “Guest network cannot access the router (www, https, ssh, telnet)”, so I adopted his iptables rules.
I still find I can ssh into my router from the ‘guest’ network.
Any idea what the problem might be, please?
Jim
How to bypass the limit of 32 mac address in the Wireless Client Filter
Thanks for the instructions. I followed the instructions and was able to successfully create a guest network but after creating that, every now and then my network stopped dropping and I had to reboot my router a couple of times before it will work again. Any ideas?
Great article!
In my case, I decided to check/test, before adding any ip rules into firewall script section. I’ve connected to the guest network, and guess what? I wasn’t able to ping any device outside the network. Also I’ve tried to ping from my normal home network to guest network – same result guest devices were not reachable. Finally, to make sure there are no any leaks between guest and home networks, I’ve installed application named “Fing” to my android mobile connected to the guest network. This application can discover other devices on same network.
So to conclude, I didn’t enter any ip rules at all, and it is secure enough.
Just make some tests, before messing up with firewall settings.
Addition to my previous post, I have to admit the router’s ip is still pingable from the guest network. But I think this isn’t an issue, because it is password protected.
I want to be able to have loopback forwarding or a firewall entry so that I can forward specific ports back from the guest network to the main network allowing me to have access to plex from the guest network etc.
Hi, with your iptables rules i’ve lost internet connection. I’ve solved by putting this rules instead:
iptables -P FORWARD ACCEPT
iptables -A FORWARD -i br1 -o br0 -j DROP
Thank you a million times for this great article. Managed to add a new wifi+ vlan for guests, and another vlan and wifi for a separate vpn.
Basically accomplished with one router what I had managed with 3 prior.
I have centurylink (CL) DSL router for internet and I use sonicwall firewall for internet which is also has WAN port connected to CL for enable internet routing from lab computer to do updates.
Now I have third router R7000 with Tomato which is hooked up to HP unmanaged pro curve switch and has internet access through sonicwall. The problem I am having is to enable VPN on tomato.
I also try to connect r7000 directly to X4 and X5 interface of soniwall and enable all zones and all routes but still failed to make VPN work. Before I try to bridge connection from CL to r7000 I and connecting r7000 to sonicwall, as last resort I wanted to find a way to setup CL – sonicwall and r7000. Perhaps, I should try to enable guest interface on r7000 and see if that could be assigned to VPN